你的代码里有多少把 Mutex?
锁是并发编程的「必需品」,却也是 bug 的温床——死锁、活锁、优先级反转,每一个都让人头疼。问题的根源在于:共享可变状态 + 并发 = 复杂度不可控。
1973 年,Carl Hewitt 提出了 Actor 模型,给出了另一种思路:既然共享状态是问题根源,那就不共享。Erlang 把这个思想发扬光大,用 6 个基本函数(spawn、send、receive、register、whereis、self)构建了支撑电信系统「九个九」可用性的并发基础设施。
在 Rust 生态中,Actix 给出了一个有趣的答案:用类型系统来「编码」Actor 模型的约束,把运行时错误转化为编译期错误。
本文不是 Actix 的使用教程,而是一次源码探索。核心问题是:当我们调用 addr.send(msg) 时,背后到底发生了什么?
注意:本文讨论的是 Actix(Actor 框架),而不是 Actix-web(Web 框架)。它们是两个独立的 crate。
第一部分:Actor 模型的本质
传统并发的困境
先看一个「经典」的并发代码:
use std::sync::{Arc, Mutex};
use std::thread;
fn main() {
let counter = Arc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Arc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
}
表面上没问题,但这段代码藏着几个深层问题:
问题 1:锁的传染性
一旦用了 Mutex,它就会像病毒一样传播。假设你有一个 UserService,它持有 Mutex<HashMap<UserId, User>>。现在你要加一个缓存,于是又多了 Mutex<Cache>。然后你发现需要在更新用户时同时更新缓存——两把锁,需要同时持有。
// 线程 A:更新用户时同步缓存
fn update_user(&self, user: User) {
let users = self.users.lock().unwrap(); // 1. 先锁 users
let cache = self.cache.lock().unwrap(); // 2. 再锁 cache
// ...
}
// 线程 B:刷新缓存时检查用户
fn refresh_cache(&self) {
let cache = self.cache.lock().unwrap(); // 1. 先锁 cache
let users = self.users.lock().unwrap(); // 2. 再锁 users ← 死锁!
// ...
}
如果时序不巧,线程 A 持有 users 等待 cache,而线程 B 恰好持有 cache 等待 users——Loss(死锁)!这种 bug 最阴险:测试时可能跑 1000 次都正常,生产环境高并发时突然卡死。
问题 2:状态的可组合性破坏
两个线程安全的操作组合起来,不一定线程安全。比如「检查然后执行」(check-then-act):
let contains = map.lock().unwrap().contains_key(&key);
if !contains {
map.lock().unwrap().insert(key, value);
}
第一次 lock() 检查后释放,第二次 lock() 插入前再获取。问题是:两次获取锁之间,另一个线程可能已经插入了同样的 key!
问题 3:锁粒度的两难
锁太粗,性能差——所有操作都串行;锁太细,复杂度爆炸——需要管理无数把锁。
核心矛盾:共享可变状态 + 并发 = 复杂度不可控
Actor 模型:另一种思路
Actor 模型的核心洞见是:既然共享状态是问题根源,那就不共享。
Actor 模型的三条基本规则:
- 一切皆 Actor:Actor 是基本计算单元
- Actor 有私有状态:只有 Actor 自己能访问
- Actor 通过消息通信:唯一的交互方式
用一个类比来理解:
传统并发像一个开放式办公室,所有人共用一个文件柜,需要「占座牌」(锁)来协调谁在用。
Actor 模型像一个隔间式办公室,每个人有自己的文件柜,通过邮件(消息)沟通。
这个类比揭示了 Actor 模型的关键特性:
| 传统并发 | Actor 模型 |
|---|---|
| 共享状态,用锁保护 | 状态隔离,无需锁 |
| 直接调用(同步) | 消息传递(异步) |
| 互斥锁死锁风险 | 无互斥锁死锁(但仍有消息死锁可能) |
| 状态可被任意修改 | 状态只能通过消息间接修改 |
为什么不需要锁? 因为每个 Actor 同一时刻只处理一条消息,状态的修改是串行的。并发发生在 Actor 之间,而不是 Actor 内部。
第二部分:Actix 的类型系统设计
Actix 用 Rust 的类型系统实现了 Actor 模型。理解这个设计,需要深入源码。
2.1 Actor trait:生命周期的契约
// actix/src/actor.rs
pub trait Actor: Sized + Unpin + 'static {
type Context: ActorContext;
fn started(&mut self, ctx: &mut Self::Context) {}
fn stopping(&mut self, ctx: &mut Self::Context) -> Running { Running::Stop }
fn stopped(&mut self, ctx: &mut Self::Context) {}
}
这个 trait 定义了三件事:
1. 关联类型 Context
type Context: ActorContext 是 Actix 设计的精髓之一。它把 Actor 的执行环境也纳入了类型系统。
为什么需要这个?因为不同的 Actor 可能需要不同的执行能力:
- 普通 Actor 用
Context<A> - 同步 Actor 用
SyncContext<A>
类型系统确保你不会把一个 Actor 放到错误的执行环境里。
2. trait bounds:Sized + Unpin + 'static
这些约束不是随便加的:
Sized:Actor 必须是大小已知的类型(不能是dyn Trait)Unpin:Actor 在被 pin 后仍可安全移动。Actix 的ContextFut在 poll 时需要通过Pin::get_mut()获取&mut self来调用 handler,Unpin约束确保这个操作是安全的'static:Actor 不能借用外部数据(不能持有非'static的引用)。这是因为 Actor 被 spawn 后独立运行,可能比任何借用的数据活得更久
3. 生命周期钩子
三个钩子方法对应 Actor 的状态机:
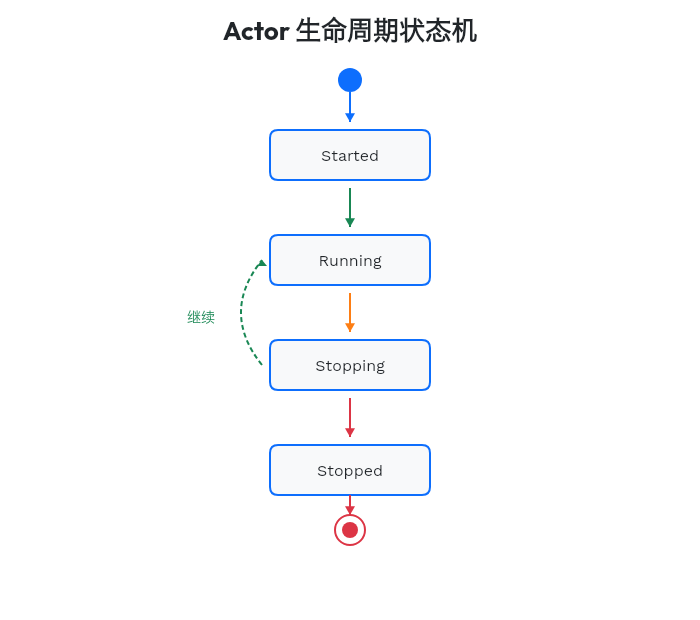
注意 stopping() 返回 Running 枚举——Actor 可以拒绝停止!这在实现「优雅关闭」时非常有用:
fn stopping(&mut self, ctx: &mut Self::Context) -> Running {
if self.pending_tasks > 0 {
Running::Continue
} else {
Running::Stop
}
}
如果还有未完成的任务,返回 Continue 拒绝停止;否则返回 Stop 允许关闭。
2.2 Message 和 Handler:类型安全的消息传递
// actix/src/handler.rs
pub trait Message {
type Result: 'static;
}
pub trait Handler<M>
where
Self: Actor,
M: Message,
{
type Result: MessageResponse<Self, M>;
fn handle(&mut self, msg: M, ctx: &mut Self::Context) -> Self::Result;
}
这个设计解决了两个关键问题:
问题 1:如何统一处理不同类型的消息?
Actor 可能需要处理多种消息。传统做法是用 enum 包装:
enum MyMessage {
Ping(Ping),
Pong(Pong),
}
每加一种消息就要改这个 enum——扩展性差。
Actix 的做法是为每种消息实现单独的 Handler<M>:
impl Handler<Ping> for MyActor { ... }
impl Handler<Pong> for MyActor { ... }
这利用了 Rust 的 trait 系统——一个类型可以实现多个 Handler<M>,每个 M 都是独立的。编译器会根据消息类型自动选择正确的 handler。
问题 2:如何处理不同的响应方式?
有时候 handler 直接返回值,有时候需要异步计算。Actix 通过 MessageResponse trait 统一处理:
pub trait MessageResponse<A: Actor, M: Message> {
fn handle(self, ctx: &mut A::Context, tx: Option<OneshotSender<M::Result>>);
}
Actix 为多种返回类型实现了这个 trait:
| 返回类型 | 行为 |
|---|---|
基本类型(i32, String, () 等) | 直接发送到 oneshot channel |
Result<T, E> | 直接发送 |
ResponseFuture<T> | spawn 一个异步任务处理 |
ResponseActFuture<A, T> | 作为 ActorFuture spawn,可访问 Actor 状态 |
AtomicResponse<A, T> | 独占 Actor,其他消息等待 |
这是 Actix 类型系统的精华——用类型编码行为。
让我们看三种典型场景:
场景 1:同步返回
直接返回值,最简单的情况:
impl Handler<GetCount> for Counter {
type Result = i32;
fn handle(&mut self, _: GetCount, _: &mut Self::Context) -> Self::Result {
self.count
}
}
场景 2:异步返回,不需要 Actor 状态
返回 ResponseFuture,异步任务独立运行,不访问 Actor:
impl Handler<FetchData> for DataService {
type Result = ResponseFuture<Result<Data, FetchError>>;
fn handle(&mut self, msg: FetchData, _: &mut Self::Context) -> Self::Result {
let url = msg.url.clone();
Box::pin(async move {
let resp = reqwest::get(&url).await?;
let data = resp.json().await?;
Ok(data)
})
}
}
注意返回类型是 Result<Data, FetchError>,用 ? 传播错误而非 unwrap()——这与文章强调的「编译期安全」理念一致。
场景 3:异步返回,需要访问 Actor 状态
返回 ResponseActFuture,异步任务完成后可以修改 Actor 状态:
impl Handler<ProcessWithState> for StatefulActor {
type Result = ResponseActFuture<Self, String>;
fn handle(&mut self, _: ProcessWithState, _: &mut Self::Context) -> Self::Result {
Box::pin(
async { "async result".to_string() }
.into_actor(self)
.map(|result, actor, _ctx| {
actor.last_result = result.clone();
result
})
)
}
}
.into_actor(self) 把普通 Future 转换为 ActorFuture,.map() 闭包中的 actor 参数就是 Actor 的可变引用。
2.3 为什么这个设计是优雅的?
回顾一下 Actix 的类型系统:
- Actor trait 定义了执行环境的契约
- Message trait 定义了消息的返回类型
- Handler trait 连接 Actor 和 Message
- MessageResponse trait 统一不同的响应方式
这些 trait 相互配合,形成了一个编译期类型安全的消息传递系统。如果你:
- 发送了 Actor 不支持的消息类型 → 编译错误
- 返回了错误的类型 → 编译错误
- 试图在错误的上下文中访问 Actor → 编译错误
这就是 Rust 类型系统的威力——把运行时错误转化为编译期错误。
第三部分:消息发送的完整链路
当你调用 addr.send(msg) 时,发生了什么?让我们追踪完整的链路。
3.1 Addr:Actor 的「门牌号」
// actix/src/address/mod.rs
pub struct Addr<A: Actor> {
tx: AddressSender<A>,
}
Addr<A> 是 Actor 的地址,但它只包含一个发送端 AddressSender<A>。为什么不直接持有 Actor 的引用?
因为 Actor 可能在另一个线程,而直接引用 &A 无法安全地跨线程传递。AddressSender 通过消息队列实现跨线程安全通信。
3.2 AddressSender:消息通道的发送端
pub struct AddressSender<A: Actor> {
inner: Arc<Inner<A>>,
sender_task: Arc<Mutex<SenderTask>>,
maybe_parked: Arc<AtomicBool>,
}
struct Inner<A: Actor> {
buffer: AtomicUsize,
state: AtomicUsize,
message_queue: Queue<Envelope<A>>,
parked_queue: Queue<Arc<Mutex<SenderTask>>>,
num_senders: AtomicUsize,
recv_task: AtomicWaker,
}
Inner 结构的字段:buffer(容量)、state(开/关 + 消息数)、message_queue(消息队列)、parked_queue(等待的发送者)、recv_task(接收者的 waker)。
这个结构揭示了几个关键设计决策:
1. 有界队列
buffer 是队列容量,默认为 16。这意味着:
- 如果队列满了,
send()会异步等待 do_send()不等待,直接入队(可能导致无限增长)try_send()不等待,队列满时返回错误
addr.send(msg).await;
addr.do_send(msg);
addr.try_send(msg)?;
三种发送方式的区别:send() 异步等待,队列满时让出执行权;do_send() 不等待,直接入队;try_send() 不等待,队列满时返回 Err。
为什么默认容量是 16? 这是一个经验值。太小会导致频繁等待,太大会浪费内存。16 在大多数场景下是合理的折中。
2. 状态编码
state: AtomicUsize 用一个整数同时编码两个信息:
const OPEN_MASK: usize = usize::MAX - (usize::MAX >> 1);
fn decode_state(num: usize) -> State {
State {
is_open: num & OPEN_MASK == OPEN_MASK,
num_messages: num & MAX_CAPACITY,
}
}
最高位表示通道是否开放,其余位表示消息数量。一个原子变量同时编码两个状态。
这个技巧避免了使用两个原子变量,减少了同步开销。
3. 背压机制
当队列满时,发送者会被「停车」(park):
fn park(&self) {
let mut sender = self.sender_task.lock();
sender.task = None;
sender.is_parked = true;
self.inner.parked_queue.push(Arc::clone(&self.sender_task));
}
发送者把自己加入 parked_queue 等待队列,等待被唤醒。
当接收者取走消息后,会唤醒一个等待的发送者:
fn unpark_one(&mut self) {
if let Some(task) = self.inner.parked_queue.pop_spin() {
task.lock().notify();
}
}
这就是背压(backpressure)——当下游处理不过来时,上游自动减速。
3.3 Envelope:类型擦除的消息封装
这是 Actix 最巧妙的设计之一。问题是:队列 Queue<Envelope<A>> 需要存储不同类型的消息,但 Rust 的类型系统要求队列元素是同一类型。
解决方案是 类型擦除:
pub struct Envelope<A: Actor>(Box<dyn EnvelopeProxy<A> + Send>);
pub trait EnvelopeProxy<A: Actor> {
fn handle(&mut self, act: &mut A, ctx: &mut A::Context);
}
struct SyncEnvelopeProxy<M> {
msg: Option<M>,
tx: Option<OneshotSender<M::Result>>,
}
impl<A, M> EnvelopeProxy<A> for SyncEnvelopeProxy<M>
where
M: Message + Send + 'static,
A: Actor + Handler<M>,
{
fn handle(&mut self, act: &mut A, ctx: &mut <A as Actor>::Context) {
if let Some(msg) = self.msg.take() {
let fut = <A as Handler<M>>::handle(act, msg, ctx);
fut.handle(ctx, self.tx.take())
}
}
}
tx 是 tokio::sync::oneshot::Sender,用于把处理结果发回给调用者。
工作原理:
- 发送消息时,把具体类型的消息包装成
SyncEnvelopeProxy<M> SyncEnvelopeProxy<M>实现了EnvelopeProxy<A>trait- 装箱成
Box<dyn EnvelopeProxy<A> + Send> - 放入
Envelope<A>中
这样,队列就可以存储任何类型的消息了——它们都被「擦除」成了 dyn EnvelopeProxy<A>。
当取出消息处理时:
fn handle(&mut self, act: &mut A, ctx: &mut A::Context) {
self.0.handle(act, ctx)
}
self.0 是 Box<dyn EnvelopeProxy<A>>,调用 handle 时动态分发到具体消息类型的 handler。
类比:这就像快递系统。无论你寄的是书、电子产品还是衣服,快递公司都用统一规格的包裹来运输。包裹上贴着收件人信息(
Actor类型)和处理指令(EnvelopeProxy),快递员不需要知道里面是什么,只需要按地址送达,由收件人自己拆箱处理。
3.4 完整的发送流程
现在我们可以画出完整的消息发送流程:

第四部分:执行引擎 —— ContextFut
消息已经进入队列,接下来是最核心的部分:如何驱动 Actor 运行?
4.1 ContextFut:Actor 的心跳
pub struct ContextFut<A, C> {
ctx: C,
act: A,
mailbox: Mailbox<A>,
wait: SmallVec<[ActorWaitItem<A>; 2]>,
items: SmallVec<[Item<A>; 3]>,
}
impl<A, C> Future for ContextFut<A, C> {
type Output = ();
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> {
// ...
}
}
ContextFut 实现了 Future trait,可以被 Tokio 运行时调度。每次 poll 就是 Actor 的一次「心跳」。
4.2 核心事件循环
让我们解析 poll 方法的核心逻辑。整个循环分为 5 个阶段:
阶段 1:首次运行时调用 started()
if !this.ctx.parts().flags.contains(ContextFlags::STARTED) {
this.ctx.parts().flags.insert(ContextFlags::STARTED);
Actor::started(&mut this.act, &mut this.ctx);
}
阶段 2:处理 wait 队列
独占式 future,完成前不处理其他消息:
while !this.wait.is_empty() && !this.stopping() {
let item = this.wait.last_mut().unwrap();
ready!(Pin::new(item).poll(&mut this.act, &mut this.ctx, cx));
this.wait.pop();
}
阶段 3:处理邮箱中的消息
this.mailbox.poll(&mut this.act, &mut this.ctx, cx);
阶段 4:处理 spawn 的 future
for item in &mut this.items {
match Pin::new(&mut item.1).poll(&mut this.act, &mut this.ctx, cx) {
Poll::Pending => {}
Poll::Ready(()) => {}
}
}
阶段 5:检查是否应该停止
if !this.alive() {
if Actor::stopping(&mut this.act, &mut this.ctx) == Running::Stop {
Actor::stopped(&mut this.act, &mut this.ctx);
return Poll::Ready(());
}
}
return Poll::Pending;
这个循环揭示了 Actor 的执行优先级:
- wait 队列最优先:
ctx.wait(future)会暂停所有其他处理 - 邮箱次之:处理接收到的消息
- spawn 的 future 最后:
ctx.spawn(future)的任务
为什么 wait 队列最优先?
wait 用于实现「原子操作」。有时候你需要 Actor 在完成某个异步操作之前不处理任何消息:
impl Handler<ImportantTask> for MyActor {
type Result = AtomicResponse<Self, ()>;
fn handle(&mut self, _: ImportantTask, _: &mut Self::Context) -> Self::Result {
AtomicResponse::new(Box::pin(
async { /* critical work */ }.into_actor(self)
))
}
}
这个 future 完成前,Actor 不处理任何其他消息。
4.3 Mailbox 的消息处理
impl<A> Mailbox<A> {
pub fn poll(&mut self, act: &mut A, ctx: &mut A::Context, task: &mut task::Context<'_>) {
while !ctx.waiting() {
match Pin::new(&mut self.msgs).poll_next(task) {
Poll::Ready(Some(mut msg)) => {
msg.handle(act, ctx);
}
Poll::Ready(None) | Poll::Pending => return,
}
}
}
}
msg.handle(act, ctx) 调用 EnvelopeProxy::handle,动态分发到具体的消息处理器。
几个关键点:
while !ctx.waiting():如果 Actor 在等待某个 future,不处理新消息poll_next:从队列取下一条消息msg.handle(act, ctx):调用具体消息的 handler
消息处理是串行的——每个 Actor 的 ContextFut 在单个任务中运行,每次 poll 按顺序处理消息。这就是为什么 Actor 内部不需要锁。
4.4 与 Tokio 的集成
Actor 启动时发生了什么?
fn start(self) -> Addr<Self>
where
Self: Actor<Context = Context<Self>>,
{
Context::new().run(self)
}
pub fn run(self, act: A) -> Addr<A> {
let fut = self.into_future(act);
let addr = fut.address();
actix_rt::spawn(fut);
addr
}
关键步骤:into_future(act) 创建 ContextFut,然后 actix_rt::spawn(fut) 把它 spawn 到 Tokio 运行时。
actix_rt::spawn(fut) 把 ContextFut 作为一个普通的 Future spawn 到 Tokio 运行时。从 Tokio 的视角看,Actor 就是一个长时间运行的 Future。
这就是 Actix 与 Tokio 的关系:Actix 是 Tokio 之上的抽象层,Actor 模型构建在 async/await 之上。
第五部分:Arbiter —— 执行环境
5.1 理解 Arbiter
默认情况下,所有通过 .start() 启动的 Actor 在当前 Arbiter 上运行(Arbiter 内部维护一个单线程 Tokio 运行时):
let worker1 = Worker { id: 1 }.start();
let worker2 = Worker { id: 2 }.start();
worker1 和 worker2 在同一个 Arbiter 上运行。这对 IO 密集型任务没问题,但 CPU 密集型任务会阻塞同一 Arbiter 上的其他 Actor。
Arbiter 是 Actix 对「执行环境」的抽象。可以创建独立的 Arbiter 来实现真正的并行:
let arbiter = Arbiter::new();
let worker3 = Worker::start_in_arbiter(&arbiter.handle(), |_| Worker { id: 3 });
Arbiter::new() 创建新线程,worker3 在独立线程中运行。
5.2 实际验证
#[actix::main]
async fn main() {
println!("Main thread: {:?}", thread::current().id());
let w1 = CpuWorker { id: 1 }.start();
let w2 = CpuWorker { id: 2 }.start();
let arb1 = Arbiter::new();
let arb2 = Arbiter::new();
let w3 = CpuWorker::start_in_arbiter(&arb1.handle(), |_| CpuWorker { id: 3 });
let w4 = CpuWorker::start_in_arbiter(&arb2.handle(), |_| CpuWorker { id: 4 });
}
w1 和 w2 在默认 Arbiter(主线程)上运行,w3 和 w4 分别在独立的 Arbiter(独立线程)上运行。
实际输出:
主线程: ThreadId(1)
[CpuWorker-1] 线程: ThreadId(1)
[CpuWorker-2] 线程: ThreadId(1) -- 同一线程
[CpuWorker-3] 线程: ThreadId(2) -- 独立线程
[CpuWorker-4] 线程: ThreadId(3) -- 独立线程
5.3 何时使用独立 Arbiter?
| 场景 | 建议 |
|---|---|
| IO 密集型(网络、数据库) | 共享 Arbiter |
| CPU 密集型(计算、加密) | 独立 Arbiter |
| 需要真正并行 | 独立 Arbiter |
| 内存敏感 | 共享 Arbiter(减少线程开销) |
第六部分:实战模式
6.1 状态机模式
Actor 天然适合实现状态机。首先定义状态和 Actor:
#[derive(Debug, Clone, PartialEq)]
enum OrderState {
Created,
Paid,
Shipped,
Delivered,
Cancelled,
}
struct OrderProcessor {
order_id: String,
state: OrderState,
}
然后定义事件作为消息:
#[derive(Debug, Message)]
#[rtype(result = "Result<OrderState, String>")]
enum OrderEvent {
Pay,
Ship,
Deliver,
Cancel,
}
最后实现状态转换逻辑:
impl Handler<OrderEvent> for OrderProcessor {
type Result = Result<OrderState, String>;
fn handle(&mut self, event: OrderEvent, _ctx: &mut Self::Context) -> Self::Result {
let (new_state, valid) = match (&self.state, &event) {
(OrderState::Created, OrderEvent::Pay) => (OrderState::Paid, true),
(OrderState::Created, OrderEvent::Cancel) => (OrderState::Cancelled, true),
(OrderState::Paid, OrderEvent::Ship) => (OrderState::Shipped, true),
(OrderState::Paid, OrderEvent::Cancel) => (OrderState::Cancelled, true),
(OrderState::Shipped, OrderEvent::Deliver) => (OrderState::Delivered, true),
_ => (self.state.clone(), false),
};
if valid {
self.state = new_state.clone();
Ok(new_state)
} else {
Err(format!("Invalid transition: {:?} -> {:?}", self.state, event))
}
}
}
为什么 Actor 适合状态机?
- 每条消息就是一个事件
handle方法就是状态转换函数- 消息串行处理,不会有并发状态修改
- 状态是私有的(天然封装)
6.2 定时任务模式
impl Actor for HealthMonitor {
type Context = Context<Self>;
fn started(&mut self, ctx: &mut Self::Context) {
ctx.run_interval(Duration::from_secs(5), |act, _ctx| {
act.check_count += 1;
println!("Health check #{}", act.check_count);
});
ctx.run_later(Duration::from_secs(10), |act, ctx| {
println!("Delayed task executed");
ctx.stop();
});
}
}
run_interval 每 5 秒执行一次健康检查;run_later 10 秒后执行一次性任务。
run_interval 和 run_later 在内部是这样实现的:
fn run_interval<F>(&mut self, dur: Duration, f: F) -> SpawnHandle
where
F: FnMut(&mut A, &mut A::Context) + 'static,
{
self.spawn(IntervalFunc::new(dur, f).finish())
}
它们本质上是 spawn 一个特殊的 ActorFuture,在指定时间触发回调。
6.3 Manager-Worker 模式
struct Manager {
workers: Vec<Addr<Worker>>,
next_worker: usize,
}
impl Handler<Task> for Manager {
type Result = ResponseFuture<TaskResult>;
fn handle(&mut self, task: Task, _ctx: &mut Self::Context) -> Self::Result {
let worker = self.workers[self.next_worker].clone();
self.next_worker = (self.next_worker + 1) % self.workers.len();
Box::pin(async move {
worker.send(task).await.unwrap()
})
}
}
轮询(round-robin)选择 worker 分发任务。
这个模式的关键点:
- Manager 持有多个 Worker 的地址
- 使用
ResponseFuture异步等待 Worker 处理 - 轮询(round-robin)分发任务
第七部分:优缺点深度分析
优点
1. 无锁并发
Actor 内部状态的修改是串行的,不需要互斥锁。这避免了互斥锁死锁和锁竞争的开销。
2. 故障隔离(需配合 Supervisor)
注意:默认情况下,Actor panic 会导致任务 abort。要实现真正的故障隔离,需要使用 Supervised trait 配合 Supervisor:
impl Supervised for MyActor {
fn restarting(&mut self, _ctx: &mut Context<Self>) {
self.count = 0;
}
}
Supervisor::start(|_| MyActor::default());
restarting() 在 Actor 重启前调用,用于重置状态。使用 Supervisor::start 启动才能实现故障隔离和自动重启。
这样,Actor panic 后会自动重启,不会影响其他 Actor。
3. 位置透明
Addr<A> 只是一个发送端,不关心 Actor 在哪个线程。理论上可以扩展到网络(分布式 Actor)。
4. 背压内置
有界队列自然形成背压,防止快生产者压垮慢消费者。
缺点
1. 调试困难
消息传递是异步的,调用栈不连续。当出现问题时,很难追踪消息的流向。
addr.send(Msg).await?;
fn handle(&mut self, msg: Msg, ctx: &mut Context<Self>) -> Self::Result {
// ...
}
发送点和处理点在代码中可能相距甚远,传统的调用栈追踪在这里完全失效。
2. 消息定义繁琐
每种交互都需要定义消息类型:
#[derive(Message)]
#[rtype(result = "String")]
struct Msg1 { /* fields */ }
impl Handler<Msg1> for MyActor {
type Result = String;
fn handle(&mut self, msg: Msg1, ctx: &mut Context<Self>) -> Self::Result {
// ...
}
}
每增加一种消息,至少要写消息定义和 Handler 实现两段代码。
3. 性能开销
消息传递比直接函数调用慢。每条消息都要:
- 装箱(Box)
- 入队
- 唤醒接收者
- 出队
- 类型擦除的动态分发
对于高频调用的场景,这个开销可能不可忽视。
4. 不适合细粒度并发
如果 Actor 粒度太细,消息传递的开销会超过实际工作。比如,不要为每个数据结构创建一个 Actor。
适用场景矩阵
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 长连接管理(WebSocket) | ✅ 非常适合 | 每个连接一个 Actor,天然隔离 |
| 状态机(订单、工作流) | ✅ 非常适合 | 事件驱动,状态隔离 |
| 任务调度 | ✅ 适合 | Manager-Worker 模式 |
| 纯计算任务 | ❌ 不适合 | 用 Rayon 等线程池更合适 |
| 高频数据处理 | ⚠️ 看情况 | 消息开销可能成为瓶颈 |
| 简单 CRUD | ❌ 不适合 | 过度设计 |
常见问题
Q:Actix 和 Tokio 的 channel 有什么区别?
A:抽象层次不同。
Tokio channel 是底层原语,你需要自己管理状态、处理并发。Actix 在此之上封装了 Actor 模型,提供了:
- 生命周期管理(started, stopping, stopped)
- 类型安全的消息处理
- 定时器、spawn 等高级功能
Q:为什么 do_send 可能导致内存耗尽?
A:因为它绕过了背压机制。
loop {
addr.do_send(Msg);
}
这个循环会无限入队,导致内存持续增长直到耗尽。
do_send 不等待队列有空位,直接入队。如果生产者持续比消费者快,队列会无限增长。
使用建议:
- 对于重要消息,用
send().await - 只在你确定消费速度够快时用
do_send
Q:如何实现 Actor 之间的双向通信?
A:互相持有对方的地址。
struct ActorA {
peer: Option<Addr<ActorB>>,
}
struct ActorB {
peer: Option<Addr<ActorA>>,
}
启动时相互注册地址:
let ctx_a = Context::<ActorA>::new();
let ctx_b = Context::<ActorB>::new();
let a = ActorA { peer: Some(ctx_b.address()) };
let b = ActorB { peer: Some(ctx_a.address()) };
ctx_a.run(a);
ctx_b.run(b);
注意循环引用:Addr<A> 内部持有 Arc,互相持有会导致两个 Actor 都无法被释放。如果其中一方可以先停止,考虑使用 WeakAddr:
struct ActorB {
peer: Option<WeakAddr<ActorA>>, // 弱引用,不阻止 A 被释放
}
// 使用时需要 upgrade
if let Some(addr) = self.peer.as_ref().and_then(|w| w.upgrade()) {
addr.do_send(Msg);
}
Q:Actor panic 了怎么办?
A:取决于你的启动方式。
默认情况下(使用 .start() 启动),Actor panic 会导致该任务 abort,发送到该 Actor 的消息会返回 MailboxError。要实现故障恢复和自动重启:
impl Supervised for MyActor {
fn restarting(&mut self, _ctx: &mut Context<Self>) {
self.count = 0;
}
}
Supervisor::start(|_| MyActor::default());
restarting() 在重启前调用,用于重置状态。Supervisor 会在 Actor panic 后自动重启它。
Q:send() 返回的错误有哪些?
A:两种 MailboxError。
match addr.send(Msg).await {
Ok(result) => { /* 正常处理 */ }
Err(MailboxError::Closed) => { /* Actor 已停止 */ }
Err(MailboxError::Timeout) => { /* 请求超时 */ }
}
MailboxError::Closed:Actor 已经停止,邮箱关闭MailboxError::Timeout:等待响应超时(使用addr.send(msg).timeout(dur)时)
重要:do_send() 不返回错误,即使 Actor 已停止也会静默丢弃消息——这是它「fire-and-forget」语义的代价。
Q:什么是「消息死锁」?如何避免?
A:两个 Actor 互相等待对方响应。
// Actor A 的 handler
impl Handler<MsgA> for ActorA {
type Result = ResponseFuture<String>;
fn handle(&mut self, _: MsgA, _: &mut Self::Context) -> Self::Result {
let addr_b = self.peer_b.clone();
Box::pin(async move {
addr_b.send(MsgB).await.unwrap() // 等待 B 响应
})
}
}
// Actor B 的 handler —— 同时也在等待 A!
impl Handler<MsgB> for ActorB {
type Result = ResponseFuture<String>;
fn handle(&mut self, _: MsgB, _: &mut Self::Context) -> Self::Result {
let addr_a = self.peer_a.clone();
Box::pin(async move {
addr_a.send(MsgA).await.unwrap() // 等待 A 响应 —— 死锁!
})
}
}
A 等待 B,B 等待 A——经典死锁,只不过不是锁死锁,而是消息死锁。
避免方法:
- 单向依赖:设计消息流向为有向无环图(DAG)
- 使用
do_send:不等待响应,改为「通知」模式 - 超时机制:
addr.send(msg).timeout(Duration::from_secs(5))
写在最后
回顾整个 Actix 的设计,有一个核心洞见值得深思:
并发的本质问题不是「如何安全地共享状态」,而是「是否真的需要共享状态」。
传统的锁机制试图在共享状态上建立秩序,但这是一条越走越窄的路——锁越多,复杂度越高,bug 越难追踪。Actor 模型另辟蹊径:通过「隔离状态 + 消息传递」,把并发问题从「如何同步」转化为「如何通信」。
Actix 更进一步,用 Rust 的类型系统把 Actor 模型的约束「固化」到了编译期:
- 发送不支持的消息?编译错误
- 返回类型不匹配?编译错误
- 跨线程传递非 Send 类型?编译错误
这和 Rust 所有权系统的哲学一脉相承:与其在运行时小心翼翼,不如在编译期一劳永逸。
理解 Actix 的关键是理解它的分层:
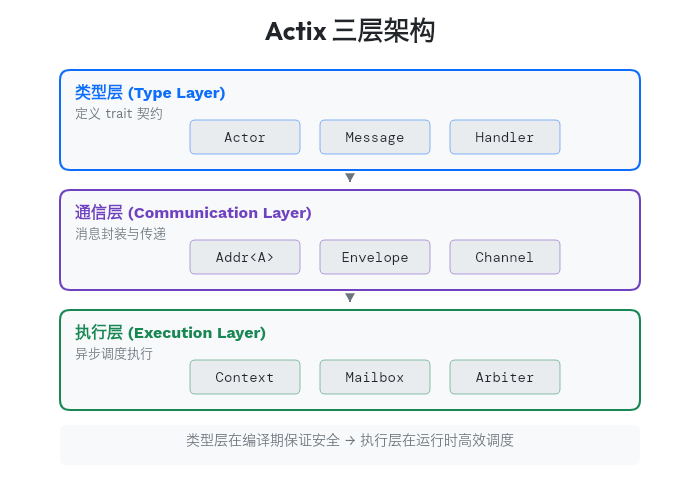
每一层都有清晰的职责,相互配合形成完整的 Actor 系统。
Actor 模型不是银弹。消息传递有开销,调试比直接调用困难,定义消息类型也略显繁琐。但当你的问题符合「多个独立状态实体需要协调」这个模式时——比如管理大量 WebSocket 连接、实现复杂的工作流状态机——它提供了一种比锁更优雅的解决方案。
下次当你发现代码里的 Mutex 越来越多时,不妨问问自己:
这些状态,真的需要共享吗?
本文基于 actix 0.13.5 源码分析,所有代码均已实际运行验证。